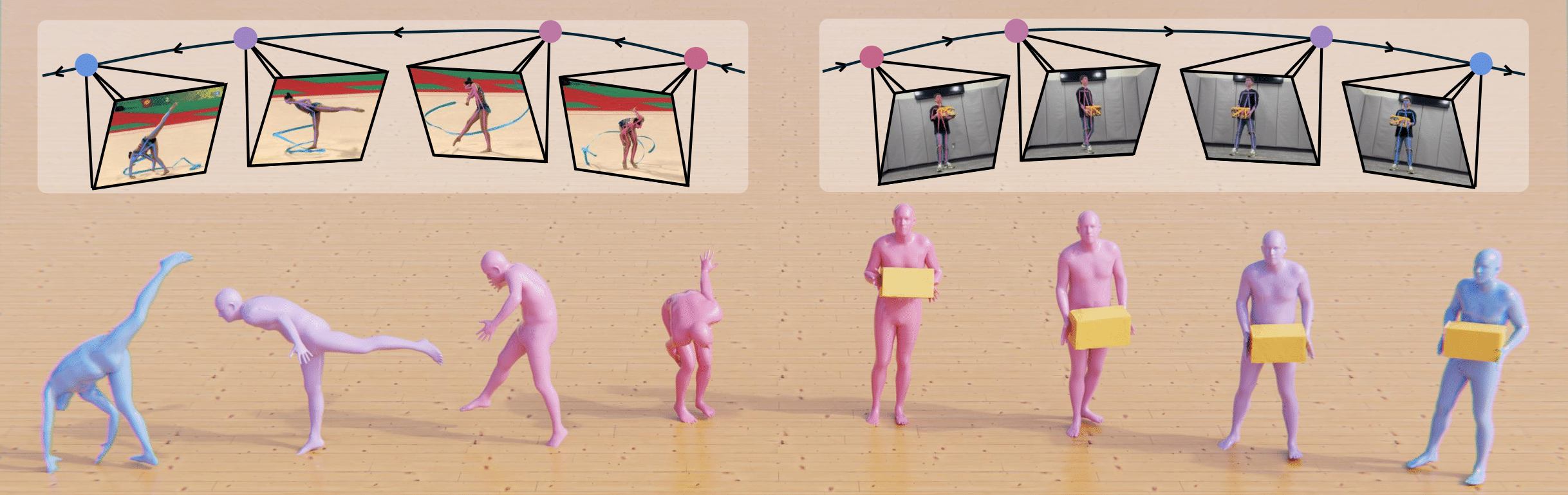AnyLift reconstructs world-coordinated 3D human motion and human-object interactions from monocular videos captured under dynamic cameras by leveraging 2D keypoints and corresponding camera trajectories as training data. It enables realistic 3D motion and interaction lifting from Internet videos.
Results on Captured Real-World Videos
Objects are reconstructed by SAM 3D.
Results on Internet Videos
Comparisons on the BEHAVE Dataset
Input object keypoints are obtained via mesh-to-mask optimization.
VisTracker takes video features as input, whereas the other methods use only extracted 2D keypoints.
Input object keypoints are obtained via reprojecting 3D ground truth.
VisTracker takes video features as input, whereas the other methods use only extracted 2D keypoints.
Comparisons on Gymnastics Videos
WHAM and GVHMR take video features as input, whereas the other methods use only extracted 2D keypoints.
Comparisons on Martial Arts Videos
WHAM and GVHMR take video features as input, whereas the other methods use only extracted 2D keypoints.
Abstract
Reconstructing 3D human motion and human-object interactions (HOI) from Internet videos is a fundamental step toward building large-scale datasets of human behavior. Existing methods struggle to recover globally consistent 3D motion under dynamic cameras, especially for motion types underrepresented in current motion-capture datasets, and face additional difficulty recovering coherent human-object interactions in 3D. We introduce a two-stage framework leveraging 2D diffusion that reconstructs 3D human motion and HOI from Internet videos. In the first stage, we synthesize multi-view 2D motion data for each domain, leveraging 2D keypoints extracted from Internet videos to incorporate human motions that rarely appear in existing MoCap datasets. In the second stage, a camera-conditioned multi-view 2D motion diffusion model is trained on the domain-specific synthetic data to recover 3D human motion and 3D HOI in the world space. We demonstrate the effectiveness of our method on Internet videos featuring challenging motions such as gymnastics, as well as in-the-wild HOI videos, and show that it outperforms prior work in producing realistic human motion and human-object interaction.
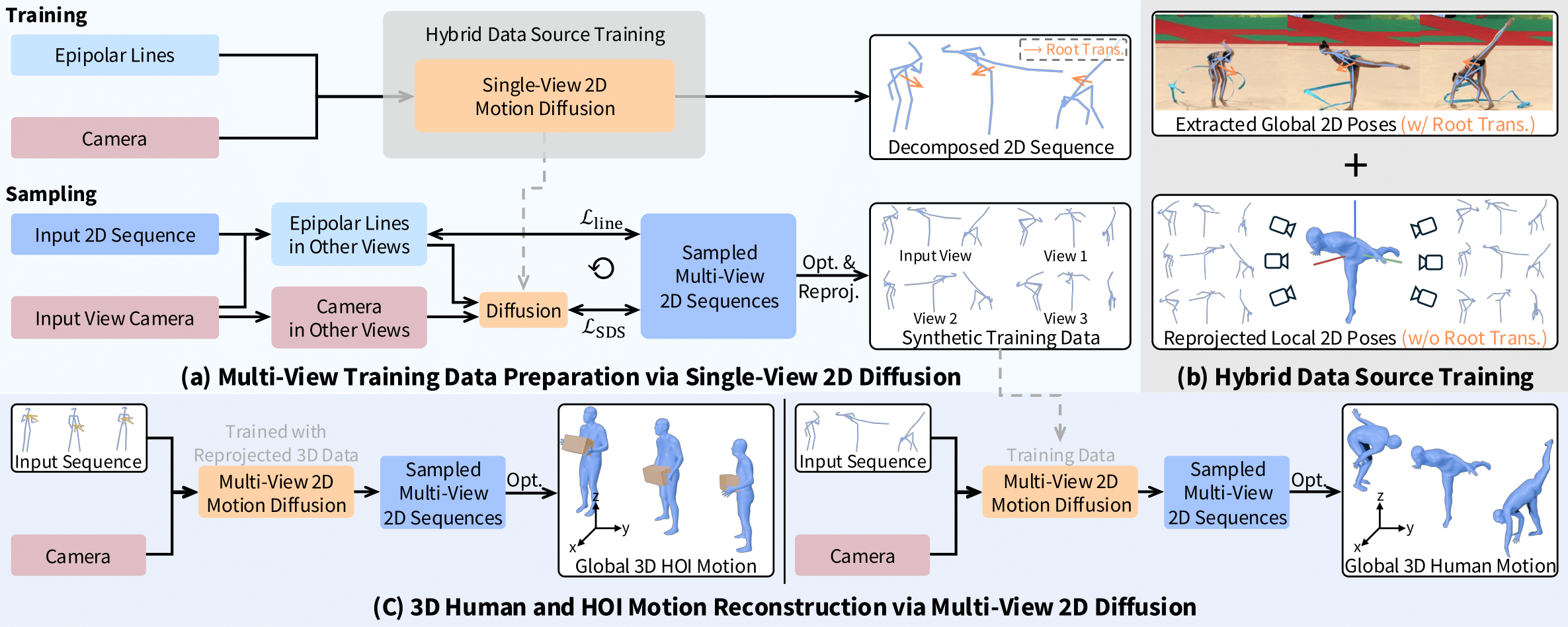
Method Overview
AnyLift reconstructs human and HOI motions by taking 2D keypoint sequences extracted from videos as input and generating consistent multi-view 2D motions. To achieve this, we first train a single-view 2D motion diffusion model to synthesize multi-view 2D training data. During training, we adopt a hybrid data-source strategy that improves viewpoint coverage by combining global 2D pose sequences from Internet videos with locally reprojected poses. Finally, we train a multi-view 2D motion diffusion model to reconstruct consistent world-coordinated 3D human and HOI motions from real-world videos.
BibTex
@inproceedings{li2026anylift,
title={Anylift: Scaling motion reconstruction from internet videos via 2d diffusion},
author={Li, Hongjie and Yu, Heng and Li, Jiaman and Yu, Hong-Xing and Adeli, Ehsan and Liu, C Karen and Wu, Jiajun},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}