ZeroHSI generates natural 3D human motion to interact with various environments (indoor/outdoor, real reconstructed/synthesized) and dynamic objects by leveraging video generation models and neural rendering, eliminating the need for paired motion-scene training data.
Generated Interactions on Real Reconstructed Scenes
Input Reconstructed 3D Scene
Generated HSI Video
4D HSI Generated by ZeroHSI
Text Prompt: "The person is lifting a vase."
Generated HSI Video
4D HSI Generated by ZeroHSI
Text Prompt: "The person is sitting on the bench."
Generated HSI Video
4D HSI Generated by ZeroHSI
Text Prompt: "The person is watering flowers with a watering can."
Generated HSI Video
4D HSI Generated by ZeroHSI
Text Prompt: "The person is playing guitar while sitting on the sofa."
Generated HSI Video
4D HSI Generated by ZeroHSI
Text Prompt: "The person is operating a lawn mower."
Generated HSI Video
4D HSI Generated by ZeroHSI
Text Prompt: "The person is cleaning the car."
Generated Long-term Interactions
Input Reconstructed 3D Scene
Long-term HSI Generated by ZeroHSI
Text Prompt 1:"The person is walking forward to the table."
Text Prompt 2:"The person is watering flowers with a watering can."
Text Prompt 3:"The person is putting down the watering can on the table."
Text Prompt 4:"The person is leaning on the table."
Long-term HSI Generated by ZeroHSI
Text Prompt 1:"The person is sitting on the bench."
Text Prompt 2:"The person is standing up."
Text Prompt 3:"The person is practice Tai Chi."
Long-term HSI Generated by ZeroHSI
Text Prompt 1:"The person is sitting on the bench."
Text Prompt 2:"The person is standing up."
Text Prompt 3:"The person is practice Tai Chi."
Long-term HSI Generated by ZeroHSI
Text Prompt 1:"The person is sitting on the bench."
Text Prompt 2:"The person is standing up."
Text Prompt 3:"The person is practice Tai Chi."
Generated Interactions on Synthetic Scenes with Objects
Input Synthetic 3D Scene
ZeroHSI (Ours)
LINGO
CHOIS
Text Prompt: "The person is playing guitar while sitting on the sofa."
ZeroHSI (Ours)
LINGO
CHOIS
Text Prompt: "The person is lifting weights."
ZeroHSI (Ours)
LINGO
CHOIS
Text Prompt: "The person is sliding while sitting on the chair."
ZeroHSI (Ours)
LINGO
CHOIS
Text Prompt: "The person is pushing shopping cart."
Generated Interactions on Synthetic Scenes
Input Synthetic 3D Scene
ZeroHSI (Ours)
TRUMANS
LINGO
Text Prompt: "The person is leaning on the ladder."
ZeroHSI (Ours)
TRUMANS
LINGO
Text Prompt: "The person is sitting on the sofa back."
ZeroHSI (Ours)
TRUMANS
LINGO
Text Prompt: "The person is sliding down the slide."
ZeroHSI (Ours)
TRUMANS
LINGO
Text Prompt: "The person is picking out snacks on the shelf."
Abstract
Human-scene interaction (HSI) generation is crucial for applications in embodied AI, virtual reality, and robotics. While existing methods can synthesize realistic human motions in 3D scenes and generate plausible human-object interactions, they heavily rely on datasets containing paired 3D scene and motion capture data, which are expensive and time-consuming to collect across diverse environments and interactions. We present ZeroHSI, a novel approach that enables zero-shot 4D human-scene interaction synthesis by integrating video generation and neural human rendering. Our key insight is to leverage the rich motion priors learned by state-of-the-art video generation models, which have been trained on vast amounts of natural human movements and interactions, and use differentiable rendering to reconstruct human-scene interactions. ZeroHSI can synthesize realistic human motions in both static scenes and environments with dynamic objects, without requiring any ground-truth motion data. We evaluate ZeroHSI on a curated dataset of different types of various indoor and outdoor scenes with different interaction prompts, demonstrating its ability to generate diverse and contextually appropriate human-scene interactions.
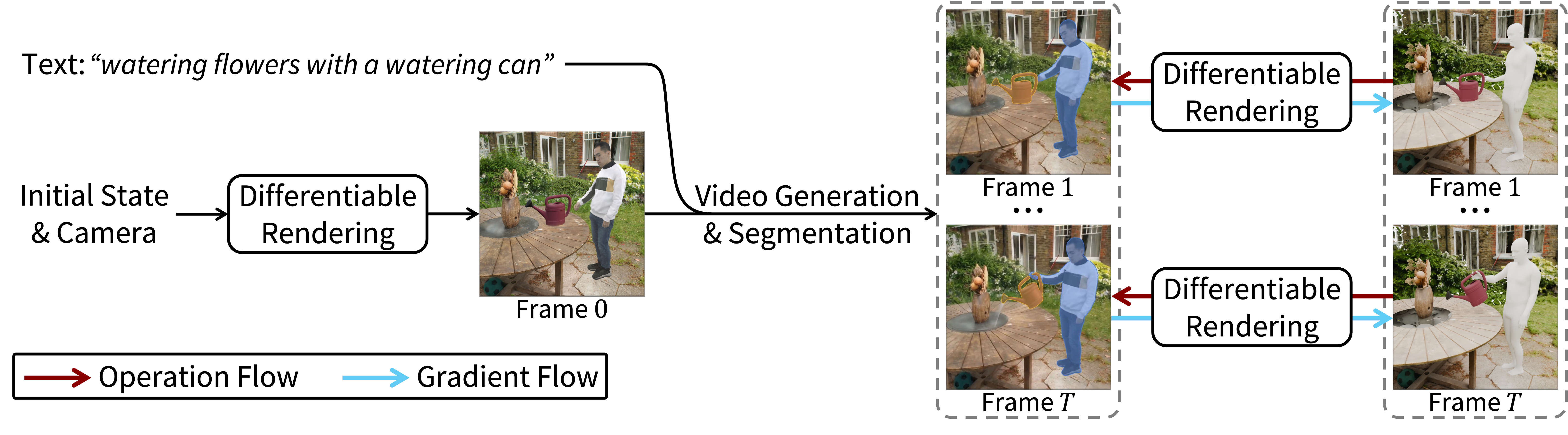
Method Overview
ZeroHSI takes a 3D scene, an interactable object, a language description, and initial states as input to synthesize both human and dynamic object motion sequences. Our approach begins with HSI video generation conditioned on the rendered initial state and text prompt. Through differentiable neural rendering, we optimize per-frame camera pose, human pose parameters, and object 6D pose by minimizing the discrepancy between the rendered and generated reference videos.
The AnyInteraction Dataset
Bedroom
Living Room
Gym
Bar
Playground
Greenhouse
Cafe
Store
Garden
Bicycle
Room
Truck
We curate the AnyInteraction dataset to evaluate zero-shot HSI synthesis. The dataset encompasses 12 diverse scenes (7 indoor and 5 outdoor) from various sources including TRUMANS, public 3D assets, and reconstructed real scenes from Mip-NeRF 360 and Tanks and Temples datasets. It features 7 types of rigid dynamic objects (Guitar, Barbell, Watering Can, Office Chair, Shopping Cart, Vase, and Mower), supporting 22 evaluation instances that include 13 static and 9 dynamic object interaction.
BibTex
@inproceedings{li2026zerohsi,
title={Zerohsi: Zero-shot 4d human-scene interaction by video generation},
author={Li, Hongjie and Yu, Hong-Xing and Li, Jiaman and Wu, Jiajun},
booktitle={International Conference on 3D Vision (3DV)},
year={2026}
}